Rules
Purpose
XTagManager computes automatically all tag names sent to AT Internet (Page tag or Click & Event tag), based on some rules described below.
When this default behaviour doesn’t meet naming requirement, some controls & completions can be managed at configuration level (see Page name for page tags or Click name for click tags).
When such Configuration flexibility is not enough, specific handling can be done in Customization JS.
Page tags
Default rule
By default, Page tag name is automatically generated from URL, by using the following pattern:
|
[protocol]://[host]/[removed path]/[account path]/[level 2 path]/[chapters path]/[page][.extension] |
|
|
[protocol]://[host] |
Protocol is
not used for naming, but
secured protocol (https) is used to setup the proper ATI
Server. |
|
[removed path] |
Leading path ignored for naming. See Path Shortener. |
|
[account path] |
Folders identifying ATI Site ID (when one site is tracked with multiple accounts). See Production. |
|
[Level 2 path] |
Folders identifying website subdivision (Level 2). See Perimeters. |
|
[chapters path]/[page] |
Remaining folders and page name. |
|
.extension |
Always ignored. |
Standard sample
|
http://www2.schneider-electric.com/sites/corporate/en/customers/satisfy-our-customers/strategic-accounts.page |
|
|
http://www2.schneider-electric.com |
Protocol and host, not used in this case to set the account. |
|
/sites/corporate |
Leading path, configured to be removed (/sites + next folder). |
|
/en |
Mapped to ATI account and server (225304, http://logi10), then removed. |
|
/customers |
Mapped to Level 2 (5), then removed. |
|
.page |
Extension, always ignored. |
The Remainder: /satisfy-our-customers/strategic accounts is converted in chapter and page name: satisfy‑our‑customers::strategic accounts
|
Possibly forbidden characters are automatically escaped to be accepted by AT Internet. |
These rules can be overridden by configuration, see Page name.
Special cases
Landing pages
As explained above, when folders are mapped to account or Level 2, they are discarded from naming.
But when, once done, there’s no remaining folders to compute the page name, it could lead to generate an empty name.
An empty name is replaced by page’s URL in ATI’s results, like Google Analytics does: in most cases, this is not what is required.
Empty name can occur with two kinds of URL:
|
Website landing page |
Example: www.mydomain.com |
|
Level 2 landing page |
Example: www.mydomain.com\Product\Range when \Product\Range is mapped to a Level 2. |
XTagManager prevents empty name as following:
|
Website landing page |
Define default page name - Example: Home |
|
Level 2 landing page |
No page name pattern
specified: use last
Level 2 folder as name – From example above:
Range |
Unclassified pages
When some parts of the website have been forgotten in Level 2 configuration, it could lead to raise tags with a Level 2 set to 0: they are called “unclassified pages”.
There are two strategies to manage them, depending on your requirements:
|
Unclassified allowed |
This is the default behavior: all
unclassified will be automatically raised with an empty name
(whatever the name computed by rules described above) |
|
Unclassified forbidden |
End Perimeters configuration with a * mapped to a
default Level 2 |
In other words, it means “when a Level 2 is expected, not having one is an issue: I record the URL to identify them. If I want to give them a name anyway, I use a dedicated Level 2”.
Clicks tags
Tag name
Default click tag name depends on click type:
|
Type |
Rule |
Example |
|
Exit |
Target URL, without protocol & parameters |
http://www.linkedin.com/groups?about=&gid=56843 |
|
Download |
[CurrentPageName]::[FileName] |
· Current page name: seg::industry::food-beverage · Link URL: /solutions/ww/en/med/pdf/1014-green-corporation.pdf Click tag name: seg::industry::food-beverage::1014- green-corporation.pdf |
|
Navigation & Action |
[CurrentPageName]::[TargetLeaf] |
· Current page name: Home · Link URL: /sites/corporate/en/support/contact/customer-contact.page Click tag name: Home::customer-contact.page |
|
Possibly forbidden characters are automatically escaped to be accepted by AT Internet. |
These rules can be overridden by configuration, see Click name.
Click type control
There are some rules checked before accepting a click tag requirement. When they are not respected, such requirement is ignored.
These rules can be overridden in customization file.
|
Type |
Rule |
Example |
|
Exit |
Target host name != host name pattern |
www.facebook.com/SchneiderElectric != www.schneider-electric.com |
|
Download |
No control, except defined filters, but by default it must be a link. |
|
|
Navigation |
Target host name = host name pattern |
www.schneider-electric.us/en/insights/= www.schneider-electric.us |
|
Action |
No control, can be any type of node. |
mailto:your.contact@schneider-electric.com |
Purpose
Most of configuration steps begin with identifying concerned pages, thanks to a given path. You’ll find below the meaning of each considered path.
Path definitions
Original
Basically, a “path” is understood as the part of URL without protocol, host name and parameters.
XTagManager calls it the Original path.
Example:
|
|
Initial
We have seen in Page Tag rules that some simplifications are done on Original path, by Configuration or by design.
XTagManager calls the result the Initial path.
Example:
From Original path: /site is removed by Path Shortener, /france is removed by Ignore Next Folder, and .page extension ignored by design:
|
|
Customized
For Production mapping, Initial path can be customized.
XTagManager calls the result the Customized path.
Example:
From Initial path, country parameter FR, is used to constitute a locale in the language folder, intended for Production mapping:
|
/fr-FR/support/faq/faq_main |
Final
If Customized path is convenient for Production mapping, it’s not necessarily the same for subsequent uses (Perimeters, Search, Sales, Clicks…).
XTagManager calls the result the Final Path, or internally the Statistics Path.
You can decide how those mappings will be achieved by setting Final Path to Initial, Customized, or the Remainder (meaning previous result minus mapped path).
Example:
|
Option |
Final path |
|
Initial |
/fr/support/faq/faq_main |
|
Customized |
/fr-FR/support/faq/faq_main |
|
Remainder |
/support/faq/faq_main |
Note that, in all cases, Customization JS can also decide to modify this path for Perimeters Scope Map: it means that the expected Path mapped in Perimeters is the same than for all Analysis.
If you want to see the Final Path used by Perimeters and Analysis, just type stat_condition._spath in the console:
![]()
|
Final path can also be modified by Perimeters Customization JS. In standard cases (only one account, no folder removed, no customization): Initial=Customized=Remainder=Original[if no extension] |
Usage definitions
Root
A Path Root is the beginning of the considered Path (whole path is also matched), understood as complete folders.
· Path Root is used by Scope Maps: with Customized Path for Production mapping, and with Final Path for Perimeters mapping.
· When ended by dot, given Path is not used as Root, but compared as exact match.
· * alone is understood as « all possible paths », and can be used by those mappings, but only once, in last position.
· * at the end of path is useless, but it is ignored when present.
Examples:
|
Path root |
Matches |
Doesn’t match |
|
/ww-EN |
/ww-EN/support/faq/faq_main |
/ww-FR/support/faq/faq_main |
|
/ww |
/ww/support/faq/faq_main |
/ww-EN/support/faq/faq_main |
|
/ww* |
Same as above |
|
|
/ww. |
/ww/ or /ww |
/ww/en |
|
* |
All path |
|
Pattern
A Path Pattern is a list of Paths separated by pipes |.
Each path can contain wildcards *. Otherwise, it is an exact match.
· Path Pattern is used by all Analysis maps: Custom Dimensions, Clicks & Events and Trackers.
· Starting by */ considers all possible folder(s) before the pattern.
· Ending by /* considers all possible folder(s) and page name after the pattern.
· Ending by * in a folder consider the value on the left as an expected root.
· * alone is understood as « all possible paths ».
Examples:
|
Path Pattern |
Matches |
Doesn’t match |
|
*/faq/faq_main |
/ww-EN/support/faq/faq_main |
/ww-EN/support/faq |
|
*/faq/* |
/ww-EN/support/faq/faq_main |
/ww-EN/support/faq_main |
|
/support/faq/* |
/support/faq/faq_main |
/ww-EN/support/faq |
|
*/product*/* |
/en/product/12358 /fr/product-range/AN2546 |
/allproducts |
|
*/all-products|*/product-listing |
/en/allproduct /fr/product-listing |
/product-listing/index |
Definition
Node Selector is an advanced system allowing to locate a set of elements in current page. It can be setup manually, or thanks to XTag Selector.
· It returns an array of nodes that can be the considered ones, or their ascendant(s): it means that final selection depends on expected node type. When not specified, expected node type is A (link).
· It is used as Nodes Collection in SELECTOR columns, but also as unique node to fill Value Indicator in VALUE or data columns or between < > in page or click names.
Syntax
Node selector allows the usage of standard css or jquery selectors, but propose also a simplification of XPath, with the following differences:
· dot class separator (.) is replaced by double dot (:),
· [@id = 'myID'] is replaced by @myID or simply myID,
· Only determinant nodes are retained in the path: if a level is not useful, it is omitted: this is the essential point, leading to short paths resistant to structure changes.
· It doesn’t provide any attribute-based filtering syntax, because this is something addressed by FILTERS columns.
It selects nodes with the following pattern:
AscendantNodeSelector/SubAscendantSelector/.../leafSelector
Where a Selector can be:
|
Selector |
Select |
||
|
id or @id |
Node using this ID, returned in a list with unique element. Note: @ is mandatory only when there’s a double dot (:) in this ID, it’s useless otherwise. |
||
|
nodeType:className.*[index] |
Node(s) with this type and class beneath current ascendant (whatever their level).
·
If nodeType is omitted, only direct
children are considered for class matching. Otherwise, all
descendants with given node type are considered.
·
. (dot) indicates that just this class is required
match will be done for class name:
·
*
indicates that a partial match will
be done for class name :
·
[index]
is optional: if missing, only first
node (index = 0) is considered for an AscendantSelector, while all
are returned for the leafSelector. Examples: |
||
|
DIV:row |
Select DIV nodes with exact class row. |
||
|
DIV:row. |
Select DIV nodes with row in class names list |
||
|
DIV:row* |
Select DIV nodes containing row in one of their class names |
||
|
DIV:row[1] |
Select second DIV nodes with exact class row. |
||
|
UL:[-1] |
Select last UL node beneath current ascendant, whatever its class. |
||
|
LI: |
Select all LI nodes beneath current ascendant, whatever their class. |
||
|
:row* |
Select nodes containing row in one of their class names, but only if they are direct child of current ascendant. |
||
|
..Selector |
Look for matching node in current node ancestors. Example: |
||
|
..DIV:row |
Look for an ancestor DIV with exact class name row. |
||
|
javascript:code |
Node(s) returned by javascript code. · code can be a function call, a variable name... everything that returns an array of nodes. · code is executed with exception management, so if it contains an error, nothing is broken. |
||
|
jquery:jquery_selector $:jquery_selector |
Node(s) returned by a jquery selector · This syntax doesn’t consider the current ascendant, if any. So it can only be used as first ascendant, or alone. · JQuery library must be loaded by the page. If not, this syntax returns an empty array. · When $ is the first character of a Definition, enter a quote before (Excel constraint). |
||
|
css:css_selector |
Node(s) returned by a css selector Examples: |
||
|
css:[title~=’flower’] |
Selects all nodes with a title attribute containing the word ‘flower’. |
||
|
css:a[href*=’.pdf’] |
Selects all link containing ‘.pdf’ in their target URL |
||
Definition
A value indicator is a set of syntaxes intended to retrieve or calculate one value, expected as text or numeric (depending on targeted field).
It is used by Visitor, Search and Sales, but also to complete names (page name, click name).
Remarks about numeric values:
· Any numeric value equal to or less
than 999,999,999.99 will be considered as being valid.
Any value above this figure will be considered as
0.
· If an expected numeric value is retrieved as text, it doesn’t matter if it contains currency (£, $, €,...), local separator (like comma instead of dot) or any comment (“VAT”, “Tax free”, ...): XTagManager cleans unexpected characters, detects local separators and convert in real number.
Node Selector
When the expected value is present in page, the value indicator can be a node selector locating its place.
· In all cases, when the selector returns more than one node, only the first is considered.
· A selected node is considered for all text it contains, including children. In other words, what you have visually selected is retrieved, minus leading and trailing spaces, html comments, and line feeds. Numeric values are cleaned as described above.
· You can add \\U or \\L at the end of the Selector to make the result Upper Case or Lower Case.
|
When it is retrieved with XTag Selector, use “For value extraction” in contextual menu. When it is used in a name (in Perimeters Pages Names or Clicks & Events Name), a Node Selector must be surrounded by < >, including Case specifiers. |
JavaScript call
|
Text or Numeric Source |
Value retrieved |
|
js:code or jstext:code |
Text returned by a JavaScript code, interpreted as string or number, depending on targeted value. It can be an expression, a function (in customization file), or any global variable declared in page. Example: js:myFunction() |
|
jsn:code or jsnum:code |
Same as before but expected value must be only a valid number. If not, zero is returned. To be used for calculation. Example: jsnum:(function(){return (totalPrice*0.2);})() >> Inline function to compute VAT |
|
selector/jsf:myFunction |
Returns myFunction(selected
node). Example: /jsfunc:(function(n){return ((n.className&&n.className.indexOf('active')>=0)?'expand':'collapse');}) >> Inline function to compute current node name |
|
When it is used in a name (in Perimeters Pages Names or Clicks & Events Name), a JavaScript call must be surrounded by < >. In all other cases, it’s optional. |
Other Text or Numercic Sources
|
Text Source |
Value retrieved |
|
#parameter |
URL parameter’s value, or empty string when missing. Example: #_requestid >> retrieve value of _requestid parameter in page’s URL. |
|
!cookie |
cookie’s value, or empty string when missing. Example: !JSESSIONID >> retrieve value of JSESSIONID cookie for current domain. |
|
\"constant |
constant string. Example: \"none >> Set none as value in all cases. |
|
999 |
Any numeric value. |
Methodology
XTag Selector allows retrieving Node(s) Selectors and Value Indicators based on them without HTML nor CSS knowledge.
It uses a complex algorithm to select only significant path and class names, in order to provide an identification that will be change resistant.
This extension can be found in Chrome store.
Instructions
1. Once installed, simply
click the toolbar icon ![]() to activate
to activate ![]()
2. Then, with the green selector, hover any element you want to select in current page.
3. If you don’t succeed to select the required area, select a smaller one inside, then click on Select Parent until you obtain the proper selection.
4. Don’t worry if you don’t directly select the A node of a link (like the IMG below): XTag Selector examines if it has a A ascendant.
5. Once required area
selected, right click on highlighted element, then choose the node
selector type:
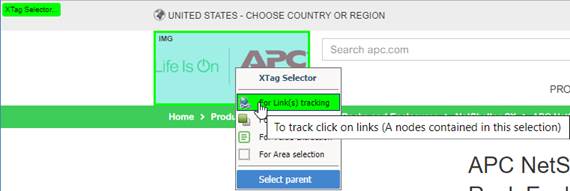
|
Menu |
Select |
|
For Links(s) tracking |
All contained links (<a>); elements. Useful for click tracking on link elements. If there is no link in your selection, you'll be warned. Note: Some href filter can be also retrieved separated by tab, to automatically populate FILTER column. |
|
For Action tracking |
The exact place where
the action is done. Useful for any clickable place which is not a
link. |
|
For Value extraction |
Text inside the selection, for Value Indicator. If there’s no text in the selection, you’ll be warned. |
|
For Area selection |
The corresponding area, whatever it contains. Can be used for Videos areas, Search results when they are not links, or general usage. |
>> Corresponding selector is copied in the clipboard, but also displayed on screen for information (until a new selection is made).
6. Paste the selector:
· Links, Action, Area: in a SELECTOR column. For Links and Actions, FILTERS and NODE TYPE can be completed as well by clipboard content.
· Value: in a VALUE column (Sites Variables, Page Variables, Visitor) or in any column expecting data (Search Keyword/Page Num, Sales) but also between < > inside page or click names.
7. To deactivate, click again
on toolbar icon ![]() or on XTag Selector...
at upper left corner, or type on
Esc key, or switch on another tab.
or on XTag Selector...
at upper left corner, or type on
Esc key, or switch on another tab.